79bob在线下载 >谷歌BigQuery



谷歌BigQuery


![]()
状态:准备生产
Grafana的BigQuery数据源
一个BigQuery DataSource插件提供支持BigQuery作为后端数据库。
快速启动
安装bigquery-grafana有多种方法。看到安装更多信息。
特点:
- 查询设置
- 原始SQL编辑器
- 查询构建器
- 宏的支持
- 额外的功能
- 表视图
- 注释
- 变量中的BQ查询
- 分片表(
tablename_YYYYMMDD) - 分区表
- 细粒度的槽位分配(在统一费率定价的项目中运行查询)
插件演示:
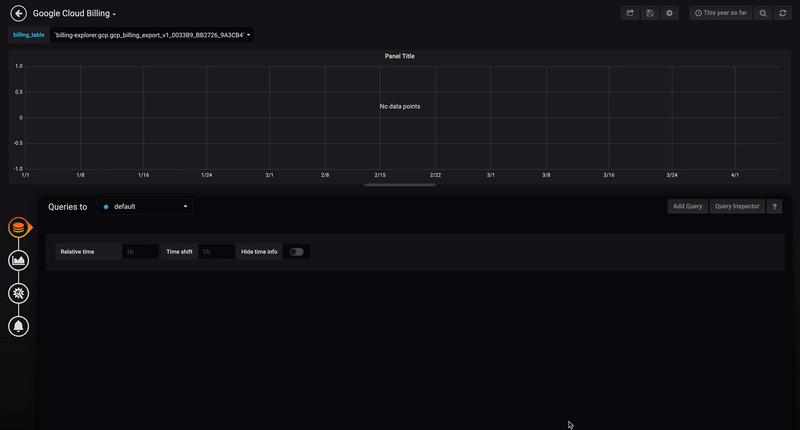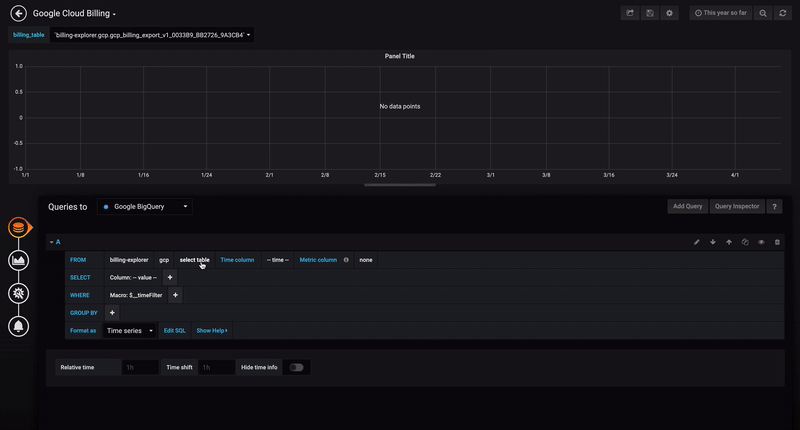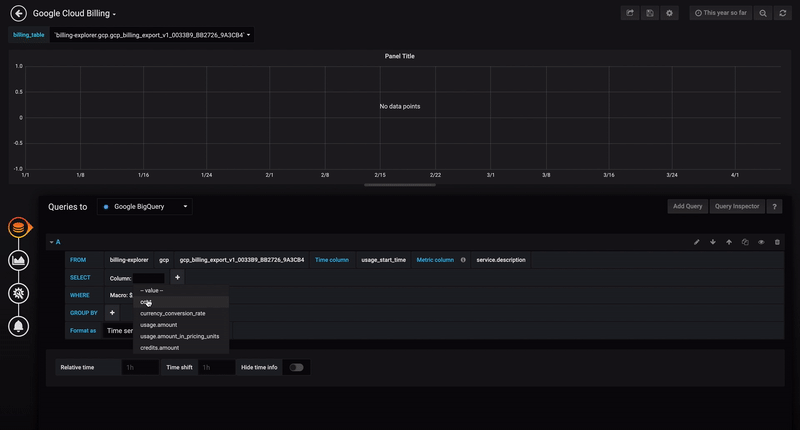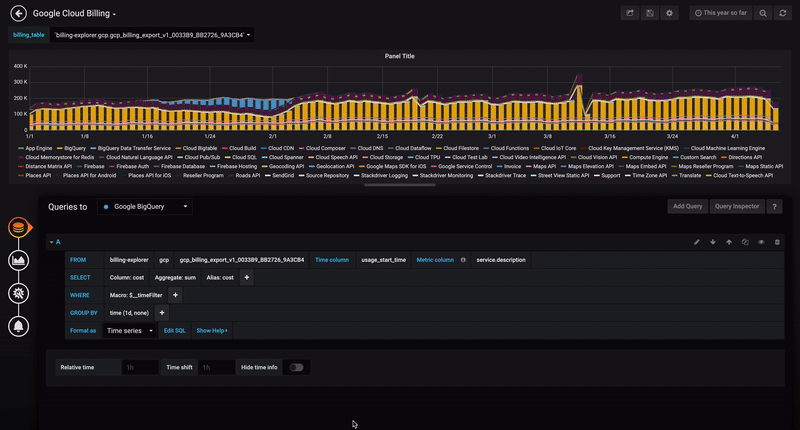
向Grafana添加数据源
- 通过单击顶部标题中的Grafana图标打开侧边菜单。
- 在侧边菜单下面
指示板您应该会找到一个名为数据源. - 单击
+添加数据源顶部标题中的按钮。 - 选择
BigQuery从类型下拉。 - 上传或粘贴服务帐户密钥文件。有关如何创建服务帐户密钥文件的步骤,请参见下面。
注意:如果你没有看到
数据源链接在您的侧菜单,这意味着您的当前用户没有管理当前组织的角色。
| 的名字 | 描述 |
|---|---|
| 的名字 | 数据源名称。这就是你在面板和查询中引用数据源的方式。 |
| 默认的 | 默认数据源意味着它将被预选为新面板。 |
| 服务帐户密钥 | GCP项目的服务帐户密钥文件。下面说明了如何创建它。 |
设置查询优先级
现在可以为每个数据源设置查询优先级“INTERACTIVE”或“BATCH”
发放文件示例
你可以通过准备系统.参见下面的配置文件示例。
apiVersion: 1数据源:
- name:
type: doitintl-bigquery-datasource access: proxy isDefault: true jsonData: authenticationType: jwt clientEmail: defaultProject: tokenUri:https://oauth2.googleapis.com/tokensecureJsonData: privateKey: |——BEGIN PRIVATE KEY——<私钥内容>——END PRIVATE KEY——version: 2 readOnly: false
身份验证
有两种方法来验证BigQuery插件——要么上传谷歌JWT文件,要么从谷歌的元数据服务器自动检索凭据。后者仅在GCE虚拟机上运行Grafana时可用。
使用谷歌业务帐户密钥文件
要使用BigQuery API进行身份验证,您需要为要显示数据的项目创建一个谷歌云平台(GCP)服务帐户。一个Grafana数据源与一个GCP项目集成。如果您想可视化来自多个GCP项目的数据,那么您可以在每个项目中赋予服务帐户权限,或者为每个GCP项目创建一个数据源。
使api
去BigQuery API而且启用API:
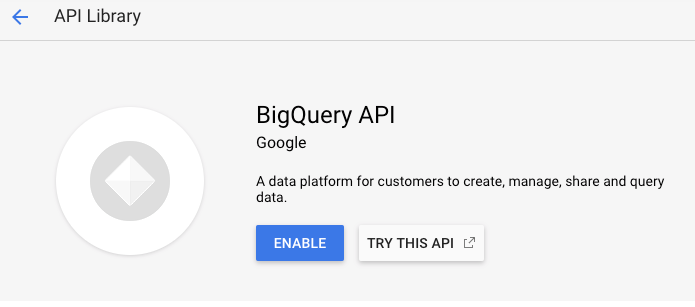
为项目创建GCP服务帐户
导航到api和服务凭证页面.
点击
创建凭证并选择服务帐户密钥.
在
创建服务帐户密钥页,选择键类型JSON.然后在服务帐户下拉菜单,选择新服务帐户选择:
一些新的字段将会出现。中为服务帐户填写名称
服务帐户名称字段,然后选择BigQuery数据查看器而且BigQuery作业用户的角色角色下拉菜单:
单击
创建按钮。将创建一个JSON密钥文件并下载到您的计算机。将此文件存储在安全的地方,因为它允许访问BigQuery数据。将它上传到数据源配置页面上的Grafana。您可以上传文件,也可以粘贴文件的内容。

文件内容将被加密并保存在Grafana数据库中。上传文件后别忘了保存!

使用GCE默认服务帐号
如果Grafana运行在一个谷歌计算引擎(GCE)虚拟机上,那么Grafana可以自动从元数据服务器检索默认凭据。这样做的好处是不需要为服务帐户生成私钥文件,也不需要将文件上传到Grafana。然而,要实现这一目标,还需要满足几个先决条件。
- 首先,您需要创建一个GCE虚拟机可以使用的Service Account。请参阅关于如何做到这一点的详细说明在这里.
- 确保GCE虚拟机实例作为您刚刚创建的服务帐户运行。参见在这里.
- 允许访问
BigQuery API范围。参见在这里.
阅读更多关于为GCE VM实例创建和启用服务帐户的信息在这里.
使用查询生成器
查询生成器提供了一个简单但用户友好的界面,以帮助您快速组合查询。构建器允许你定义查询的基本部分,常见的有:
要查询的表
时间场和度规场
WHERE子句——要么使用预定义的宏之一,以加快您的写作速度,要么设置您自己的表达式。现有支持的宏有:
a.带有最近7天的宏$__timeFiler示例:
WHERE ' createDate ' BETWEEN TIMESTAMP_MILLIS (1592147699012) AND TIMESTAMP_MILLIS (1592752499012) AND _PARTITIONTIME >= ' 20-06-14 18:14:59' AND _PARTITIONTIME < ' 20-06-21 18:14:59'b.宏$__timeFrom与最近7天的例子:
WHERE ' createDate ' > TIMESTAMP_MILLIS (1592223758609) AND _PARTITIONTIME >= ' 20-06-15 15:22:38' AND _PARTITIONTIME < ' 20-06-22 15:22:38'c.使用最近7天的宏$__timeTo示例:
WHERE ' createDate ' < TIMESTAMP_MILLIS (1592828659681) AND _PARTITIONTIME >= '2020-06-15 15:24:19' AND _PARTITIONTIME < '2020-06-22 15:24:19'现在可以在原始sql模式下使用timeFilter宏
- GROUP BY选项——你可以使用预定义的宏,或者使用你的查询中的一个字段。
- 按选项订购
注意:如果您的处理位置不是默认的美国位置,请从查询构建器右上右下的处理位置下拉菜单中设置您的位置
故障排除
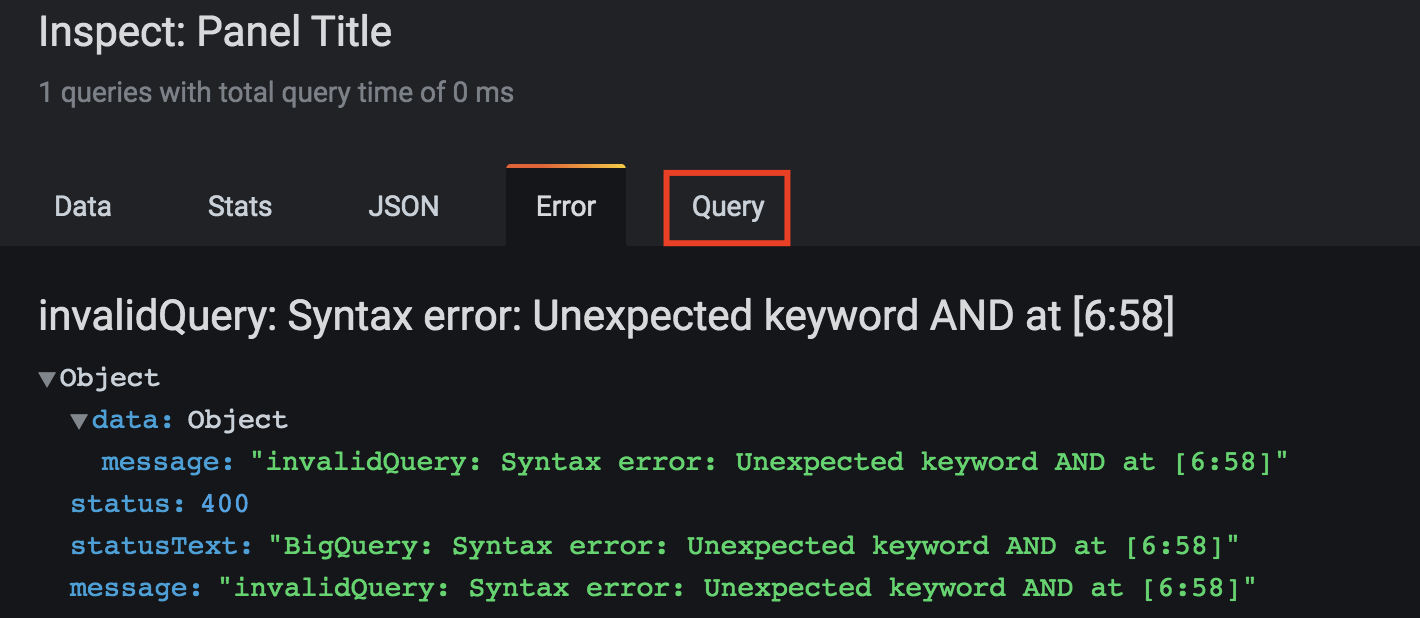
查看查询
- 使用位于查询生成器顶部的查询检查器

- 查询检查器使您能够查看干净的查询并排除SQL错误
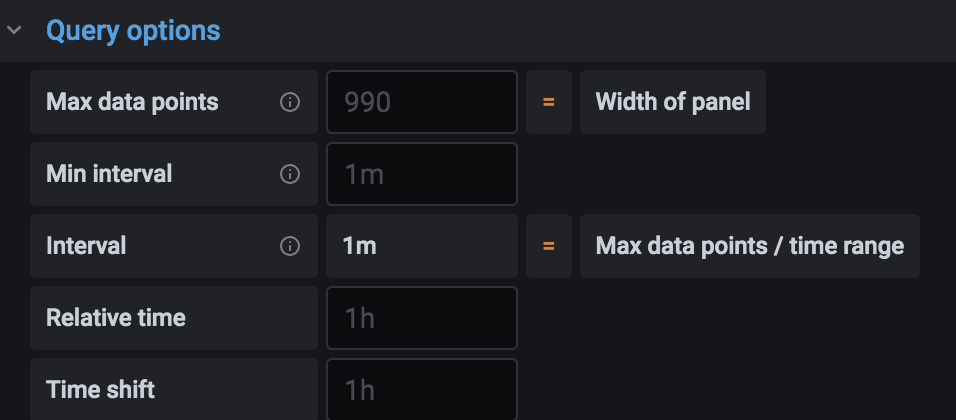
Query生成器附带了一组默认值,这些值可以从Query builder的顶部进行控制
构建
构建工作与Yarn:
开发建设
Yarn运行构建:dev生产制造
纱线运行构建:prod可以使用Jest运行测试:
纱线运行试验贡献
看到贡献指南.
许可证
看到许可文件.
Grafana Cloud Advanced / Grafana Enterprise
- 可与Grafana Cloud Advanced计划或Grafana Enterprise许可证一起使用
- 访问所有企业插件
- 在您自己的基础架构上运行完全管理或自我管理
在Grafana Cloud上安装谷歌BigQuery:
在Grafana Cloud实例上安装插件是一键式安装;更新也是一样。很酷,对吧?
注意,可能需要1分钟才能看到插件显示在Grafana中。
在Grafana Cloud实例上安装插件是一键式安装;更新也是一样。很酷,对吧?
注意,可能需要1分钟才能看到插件显示在Grafana中。
在Grafana Cloud实例上安装插件是一键式安装;更新也是一样。很酷,对吧?
注意,可能需要1分钟才能看到插件显示在Grafana中。
在Grafana Cloud实例上安装插件是一键式安装;更新也是一样。很酷,对吧?
注意,可能需要1分钟才能看到插件显示在Grafana中。
在Grafana Cloud实例上安装插件是一键式安装;更新也是一样。很酷,对吧?
注意,可能需要1分钟才能看到插件显示在Grafana中。
欲了解更多信息,请访问docs插件安装.
安装在本地Grafana上:
对于本地实例,通过一个简单的CLI命令安装和更新插件。插件不会自动更新,但是当您的Grafana中有更新可用时,您会收到通知。
1.安装数据源
使用grafana-cli工具从命令行安装谷歌BigQuery:
安装Grafana-cli插件插件将被安装到你的grafana plugins目录中;默认是/var/lib/grafana/plugins.关于cli工具的更多信息.
2.配置数据源
从Grafana主菜单访问,可以立即在data sources部分中添加新安装的数据源。
接下来,单击右上角的Add数据源按钮。中的数据源将可供选择类型选择框。
要查看已安装数据源的列表,请单击插件项目在主菜单。核心数据源和已安装数据源都会出现。
