Apache气流集成Grafana云
Apache气流是一个开源平台,通过编程方式编写,调度,和监控工作流,使复杂的数据管道和任务的编排依赖性。这种集成Grafana云允许用户收集指标、调度日志和日志监控一个Apache气流系统的任务。
指标包括DAG(有向无环图)失败,DAG持续时间,任务失败,任务持续时间,调度程序细节,遗嘱执行人任务和Apache气流系统任务池槽。
这种集成支持Apache气流2.5.0 +版本。
这种集成包括4有用的警报和1预构建仪表盘来帮助监控和可视化Apache气流指标和日志。
在你开始之前
为了集成正确工作,气流必须设置给StatsD指标。
气流向StatsD指标设置
首先你必须安装StatsD要求:
pip安装“apache-airflow [statsd]”另外,以下行必须添加到您的airflow.cfg:
[标准]statsd_on = True statsd_host = localhost statsd_port = 8125 statsd_prefix =气流安装Apache气流集成Grafana云
- 在你Grafana云栈,点击连接在左边的菜单中。
- 找到Apache气流并点击打开集成的瓷砖。
- 审查的先决条件配置细节选项卡并设置Grafana代理发送Apache气流指标和日志Grafana云实例。
- 点击安装添加这个集成的预构建的仪表板和警报Grafana云实例,你可以开始监视Apache气流设置。
安装后配置Apache气流集成
使指标生成后,指示Grafana代理刮你的Apache气流系统。
一定要改变listen_udp根据您的环境的片段。
如果你想在您的仪表板显示日志和相关指标信号单窗格玻璃,确保以下几点:
工作和实例标签的值必须匹配的Apache气流集成和日志刮代理配置文件中配置。工作必须设置为集成/ apache-airflow。确保工作下代理relabel_configs匹配工作标签下的日志static_configs以及pipeline_stages匹配选择器。实例标签必须设置一个值,惟一地标识您的Apache气流系统。确保实例下代理statsd_exporter匹配实例标签下的日志static_configs以及pipeline_stages匹配选择器。
集成:statsd_exporter:启用:真正的实例:“< your-instance-name >”listen_udp:“< your-instance-hostname >: 8125”scrape_interval: 60年代scrape_integration:真正的relabel_configs: - target_label:工作替代:“集成/ apache-airflow”mapping_config:映射:-匹配:“airflow.dag。*。*。持续时间”match_metric_type:观察者的名字:“airflow_dag_task_duration”标签:dag_id:“$ 1”task_id:“$ 2”-匹配:“airflow.dagrun.duration.success。*”match_metric_type:观察者的名字:“airflow_dagrun_duration_success”标签:dag_id:“$ 1”-匹配:“airflow.dagrun.duration.failed。*”match_metric_type:观察者的名字:“airflow_dagrun_duration_failed”标签:dag_id:“$ 1”-比赛:“airflow.ti.start。*。*”match_metric_type:计数器的名字:“airflow_task_start_total”标签:dag_id:“$ 1”task_id:“$ 2”-匹配:“airflow.ti.finish。*。*。*”match_metric_type:计数器的名字:“airflow_task_finish_total”标签:dag_id:“$ 1”task_id:“2”状态:“3美元-匹配:airflow.dagrun.schedule_delay。*”match_metric_type:观察者的名字:“airflow_dagrun_schedule_delay”标签:dag_id:“$ 1”-匹配:“airflow.pool.running_slots。* match_metric_type:指标名称:“airflow_pool_running_slots”标签:pool_name:“$ 1”-匹配:“airflow.pool.queued_slots。*”match_metric_type:指标名称:“airflow_pool_queued_slots”标签:pool_name:“$ 1”-匹配:“airflow.pool.open_slots。*”match_metric_type:指标名称:“airflow_pool_open_slots”标签:pool_name:“$ 1”-匹配:“airflow.pool.starving_tasks。*”match_metric_type:指标名称:“airflow_pool_starving_tasks”标签:pool_name:“$ 1”日志:configs: - scrape_configs: - job_name: integrations/apache-airflow static_configs: - targets: [localhost] labels: job: integrations/apache-airflow instance: __path__: /logs/dag_id=*/**/*.log - targets: [localhost] labels: job: integrations/apache-airflow instance: __path__: /logs/scheduler/latest/*.py.log pipeline_stages: - match: selector: '{job="integrations/apache-airflow",instance=""}' stages: - regex: source: filename expression: "/logs/dag_id=(?P\\S+?)/.*/task_id=(?P\\S+?)/.*log" - labels: dag_id: task_id: - match: selector: '{job="integrations/apache-airflow",instance=""}' stages: - regex: source: filename expression: "/logs/scheduler/latest/(?P\\S+?)\\.log" - labels: dag_file: - multiline: # match on timestamp. Format should be like '[2023-05-09T11:58:53.205+0000]' firstline: '\[\d+-\d+-\d+T\d+:\d+:\d+\.\d+\+\d+\]' 配置片段Grafana代理
下面集成,插入下面的线条和改变url根据您的环境:
statsd_exporter:启用:真正的实例:“< your-instance-name >”listen_udp:“< your-instance-hostname >: 8125”scrape_interval: 60年代scrape_integration:真正的relabel_configs: - target_label:工作替代:“集成/ apache-airflow”mapping_config:映射:-匹配:“airflow.dag。*。*。持续时间”match_metric_type:观察者的名字:“airflow_dag_task_duration”标签:dag_id:“$ 1”task_id:“$ 2”-匹配:“airflow.dagrun.duration.success。*”match_metric_type:观察者的名字:“airflow_dagrun_duration_success”标签:dag_id:“$ 1”-匹配:“airflow.dagrun.duration.failed。*”match_metric_type:观察者的名字:“airflow_dagrun_duration_failed”标签:dag_id:“$ 1”-比赛:“airflow.ti.start。*。*”match_metric_type:计数器的名字:“airflow_task_start_total”标签:dag_id:“$ 1”task_id:“$ 2”-匹配:“airflow.ti.finish。*。*。*”match_metric_type:计数器的名字:“airflow_task_finish_total”标签:dag_id:“$ 1”task_id:“2”状态:“3美元-匹配:airflow.dagrun.schedule_delay。*”match_metric_type:观察者的名字:“airflow_dagrun_schedule_delay”标签:dag_id:“$ 1”-匹配:“airflow.pool.running_slots。* match_metric_type:指标名称:“airflow_pool_running_slots”标签:pool_name:“$ 1”-匹配:“airflow.pool.queued_slots。*”match_metric_type:指标名称:“airflow_pool_queued_slots”标签:pool_name:“$ 1”-匹配:“airflow.pool.open_slots。*”match_metric_type:指标名称:“airflow_pool_open_slots”标签:pool_name:“$ 1”-匹配:“airflow.pool.starving_tasks。*”match_metric_type:指标名称:“airflow_pool_starving_tasks”标签:pool_name:“$ 1”下面logs.configs.scrape_configs根据您的环境,插入下面的线。
- job_name:集成/ apache-airflow static_configs:目标:(localhost)标签:工作:集成/ apache-airflow实例:< your-instance-name > __path__: < airflow_home > / logs / dag_id = * / * * / *。日志——目标(localhost):标签:工作:集成/ apache-airflow实例:< your-instance-name > __path__: < airflow_home > / logs /调度器最新/ / * . py。日志pipeline_stages: -匹配:选择器:“{工作=“集成/ apache-airflow”实例= < your-instance-name >“}”阶段:-正则表达式:来源:文件名的表情:“< airflow_home > / logs / dag_id = (P < dag_id > \ \ S + ?) / . * / task_id = (P < task_id > \ \ S + ?) /。*日志”——标签:dag_id: task_id: -匹配:选择器:“{工作=“集成/ apache-airflow”实例= < your-instance-name >“}”阶段:-正则表达式:来源:文件名的表情:“< airflow_home > / logs /调度器/最近/ (P < dag_file > \ \ S + ?) \ \。日志”——标签:dag_file:多行:#匹配时间戳。格式应该像“[2023 - 05 - 09年t11:58:53.205 + 0000]的得力:“\ [\ d + - \ d + \ d + T \ d +: \ d +: \ d + \ \ d + \ + \ d + \]”完整的示例配置Grafana代理
请参考以下Grafana代理配置一个完整的示例,其中包含所有的片段用于Apache气流集成。这个例子还包括指标被发送到监控你Grafana代理实例。
集成:prometheus_remote_write: - basic_auth:密码:< your_prom_pass >用户名:< your_prom_user > url: < your_prom_url >代理:启用:真正的relabel_configs: -行动:取代source_labels:——agent_hostname target_label:实例——行动:取代target_label:工作替代:“集成/代理来检查”metric_relabel_configs: -行动:保持正则表达式:(prometheus_target_。* | prometheus_sd_discovered_targets | agent_build。* | agent_wal_samples_appended_total | process_start_time_seconds) source_labels: - __name__ #这里添加任何片段,属于“集成”部分。#正确的缩进,复制粘贴片段从Grafana初云。statsd_exporter:启用:真正的实例:“< your-instance-name >”listen_udp:“< your-instance-hostname >: 8125”scrape_interval: 60年代scrape_integration:真正的relabel_configs: - target_label:工作替代:“集成/ apache-airflow”mapping_config:映射:-匹配:“airflow.dag。*。*。持续时间”match_metric_type:观察者的名字:“airflow_dag_task_duration”标签:dag_id:“$ 1”task_id:“$ 2”-匹配:“airflow.dagrun.duration.success。*”match_metric_type:观察者的名字:“airflow_dagrun_duration_success”标签:dag_id:“$ 1”-匹配:“airflow.dagrun.duration.failed。*”match_metric_type:观察者的名字:“airflow_dagrun_duration_failed”标签:dag_id:“$ 1”-比赛:“airflow.ti.start。*。*”match_metric_type:计数器的名字:“airflow_task_start_total”标签:dag_id:“$ 1”task_id:“$ 2”-匹配:“airflow.ti.finish。*。*。*”match_metric_type:计数器的名字:“airflow_task_finish_total”标签:dag_id:“$ 1”task_id:“2”状态:“3美元-匹配:airflow.dagrun.schedule_delay。*”match_metric_type:观察者的名字:“airflow_dagrun_schedule_delay”标签:dag_id:“$ 1”-匹配:“airflow.pool.running_slots。* match_metric_type:指标名称:“airflow_pool_running_slots”标签:pool_name:“$ 1”-匹配:“airflow.pool.queued_slots。*”match_metric_type:指标名称:“airflow_pool_queued_slots”标签:pool_name:“$ 1”-匹配:“airflow.pool.open_slots。*”match_metric_type:指标名称:“airflow_pool_open_slots”标签:pool_name:“$ 1”-匹配:“airflow.pool.starving_tasks。*”match_metric_type:指标名称:“airflow_pool_starving_tasks”标签:pool_name:“$ 1”日志:configs: - clients: - basic_auth: password: username: url: name: integrations positions: filename: /tmp/positions.yaml scrape_configs: # Add here any snippet that belongs to the `logs.configs.scrape_configs` section. # For a correct indentation, paste snippets copied from Grafana Cloud at the beginning of the line. - job_name: integrations/apache-airflow static_configs: - targets: [localhost] labels: job: integrations/apache-airflow instance: __path__: /logs/dag_id=*/**/*.log - targets: [localhost] labels: job: integrations/apache-airflow instance: __path__: /logs/scheduler/latest/*.py.log pipeline_stages: - match: selector: '{job="integrations/apache-airflow",instance=""}' stages: - regex: source: filename expression: "/logs/dag_id=(?P\\S+?)/.*/task_id=(?P\\S+?)/.*log" - labels: dag_id: task_id: - match: selector: '{job="integrations/apache-airflow",instance=""}' stages: - regex: source: filename expression: "/logs/scheduler/latest/(?P\\S+?)\\.log" - labels: dag_file: - multiline: # match on timestamp. Format should be like '[2023-05-09T11:58:53.205+0000]' firstline: '\[\d+-\d+-\d+T\d+:\d+:\d+\.\d+\+\d+\]' metrics: configs: - name: integrations remote_write: - basic_auth: password: username: url: scrape_configs: # Add here any snippet that belongs to the `metrics.configs.scrape_configs` section. # For a correct indentation, paste snippets copied from Grafana Cloud at the beginning of the line. global: scrape_interval: 60s wal_directory: /tmp/grafana-agent-wal 指示板
Apache气流集成安装下列指示板在你Grafana云实例来帮助监视您的系统。
- Apache气流概述
Apache气流概述(通用)
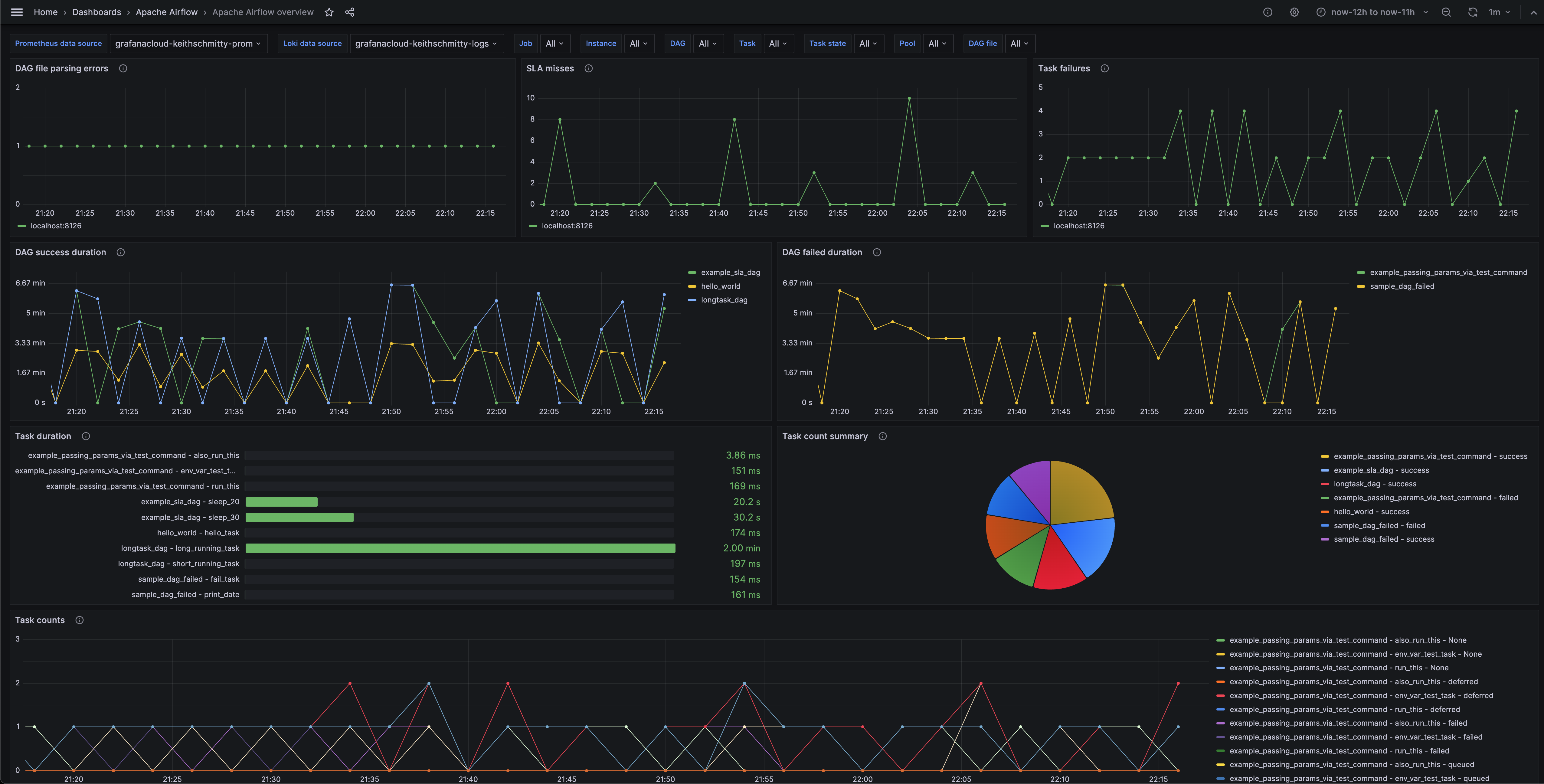
Apache气流概述(调度)
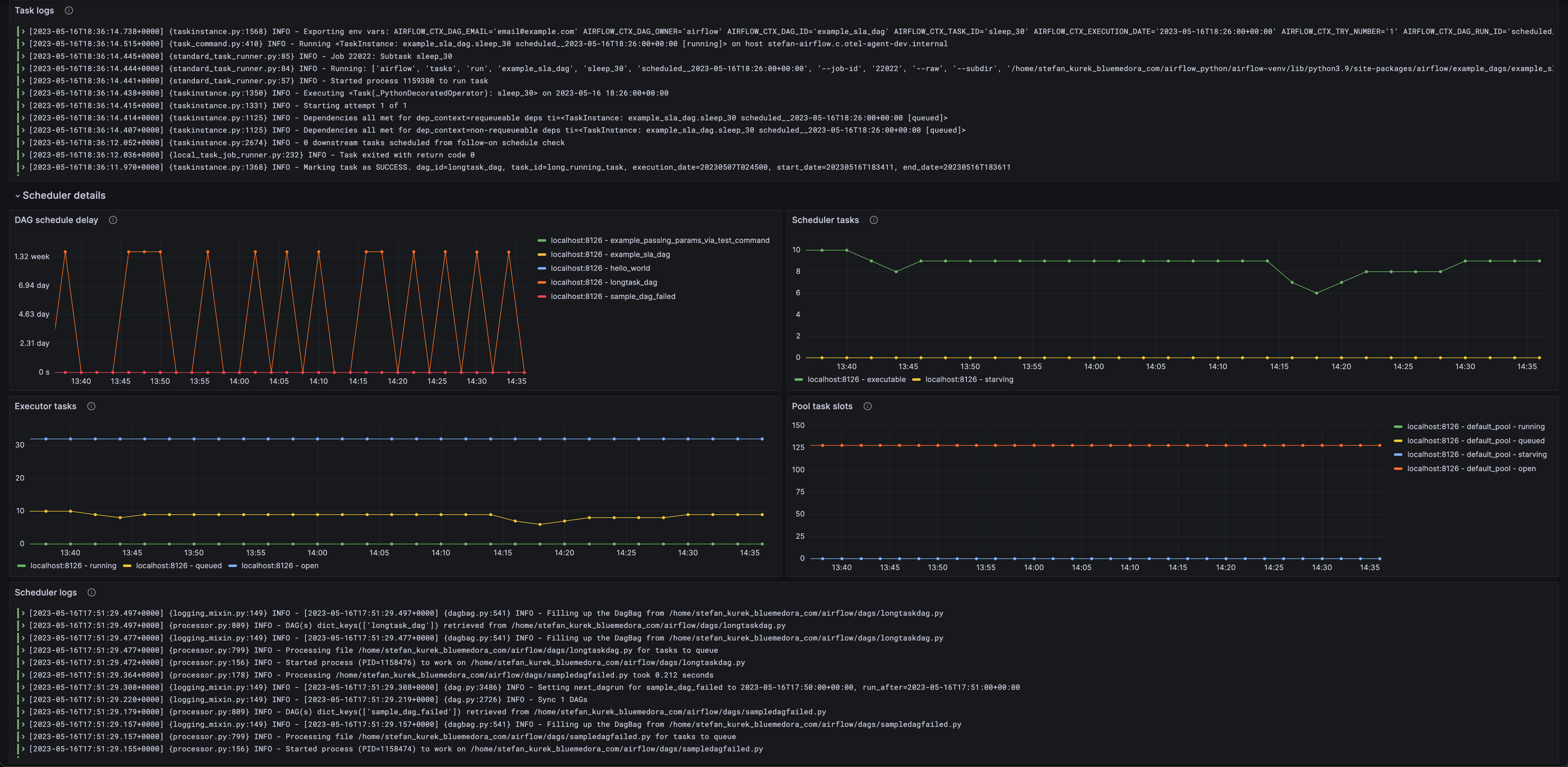
警报
Apache气流集成包括以下有用的提醒:
| 警报 | 描述 |
|---|---|
| ApacheAirflowStarvingPoolTasks | 关键:有饿死的任务中发现Apache气流池。 |
| ApacheAirflowDAGScheduleDelayWarningLevel | 警告:DAG调度时间DAG运行时间的延迟已经达到警告阈值。 |
| ApacheAirflowDAGScheduleDelayCriticalLevel | 关键:延迟DAG调度时间DAG运行时间已达到临界阈值。 |
| ApacheAirflowDAGFailures | 关键:有DAG故障检测。 |
指标
Apache气流集成提供的最重要的指标,使用预先构建的仪表板和普罗米修斯警报,如下:
- airflow_dag_processing_import_errors
- airflow_dag_task_duration_count
- airflow_dag_task_duration_sum
- airflow_dagrun_duration_failed_count
- airflow_dagrun_duration_failed_sum
- airflow_dagrun_duration_success_count
- airflow_dagrun_duration_success_sum
- airflow_dagrun_schedule_delay_count
- airflow_dagrun_schedule_delay_sum
- airflow_executor_open_slots
- airflow_executor_queued_tasks
- airflow_executor_running_tasks
- airflow_pool_open_slots
- airflow_pool_queued_slots
- airflow_pool_running_slots
- airflow_pool_starving_tasks
- airflow_scheduler_tasks_executable
- airflow_scheduler_tasks_starving
- airflow_sla_missed
- airflow_task_finish_total
- airflow_task_start_total
- airflow_ti_failures
- dag_file
更新日志
# 2023年8月发布,*添加正则表达式过滤日志数据源# 0.0.1 - 2023年6月*最初版本成本
气流通过连接您的Apache实例Grafana云,你可能会产生费用。查看信息活动系列的数量Grafana云账号用途指标包括在每个云层,明白了活跃的系列和数据处理机使用和云线价格。


