大多数人都在测试他们的应用程序,日志是进入可观察性世界的简单的第一步,然后是度量。
跟踪落后于这两种模式,可能比其他可观察性模式使用得少一些。
我们希望改变这种状况。
bob电竞频道Grafana Labs最近推出了一个易于操作、高规模、低成本的分布式跟踪后端:Grafana节奏.Tempo的唯一依赖是对象存储。与其他跟踪后端不同,Tempo可以在没有难以管理的Elasticsearch或Cassandra集群的情况下实现大规模的跟踪。Tempo支持仅通过跟踪id进行搜索;原木和普罗米修斯样品可以有效地寻找痕迹。简而言之,Tempo允许我们以比以往更低的操作成本和复杂性尽可能地扩展跟踪。
2月4日,Grafanbob电竞频道a Labs高级后端开发人员Joe Elliott将主持一个关于如何使用Tempo开始跟踪的网络研讨会,以及如何无缝连接度量、日志和跟踪的Grafana集成。你可以在这里注册活动.
与此同时,下面简要介绍分布式跟踪的基本知识。除了解释跟踪是如何工作的,我们还讨论了为什么开发人员应该致力于将分布式跟踪合并到他们的应用程序中,以及如何投资金钱和时间来构建基础设施和安装用于跟踪的代码,从而提高应用程序的性能。
可观察性基础:度量和日志
在讨论跟踪之前,让我们先回顾一下度量和日志,这将有助于为跟踪可以为您做什么以及它可以填补什么漏洞奠定基础。

指标的强大力量?他们aggregatable。它们是我们系统行为的集合。因此,它们易于查询,而且存储成本低。它们通常存储为时间序列数据,即时间戳和值。压缩非常好,这使得存储和查询非常容易,非常快。
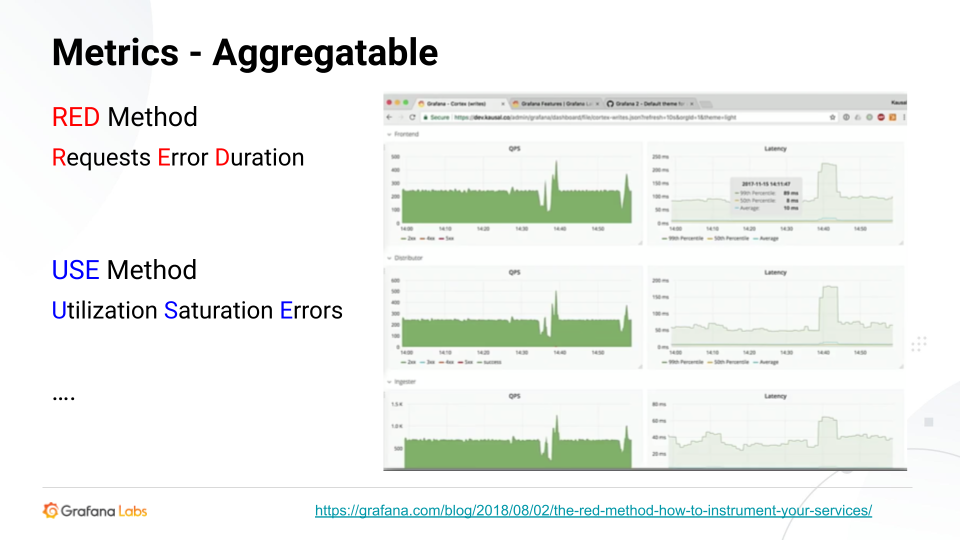
然而,在讨论度量时,基数是一个主要因素,特别是当它太多的时候。当添加了太多指标或标签时,就会发生基数爆炸,这反过来又会增加存储成本、索引大小和查询速度。简而言之,你已经打败了参数的意义。
指标应该是简单的。我们有覆盖大量数据的小索引,以及覆盖应用程序中大量行为的小数据。因此,我们希望将指标聚合起来。这就是指标的意义所在;这就是我们存储它们并查询它们的原因。
除了度量之外,日志也是一种重要的工具形式,可以帮助评估服务的运行状况。
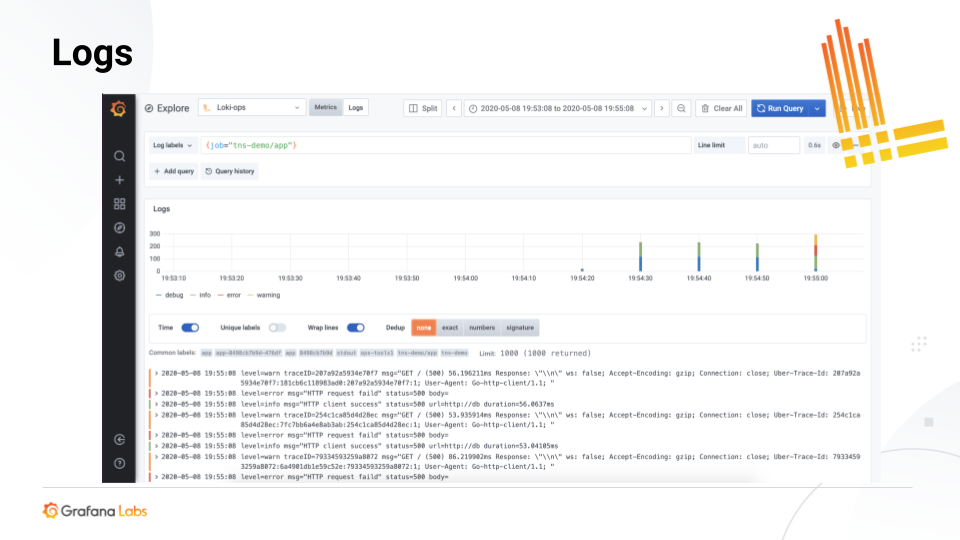
bob电竞频道Grafana实验室使用Grafana洛基这是一个受Prometheus启发的水平可扩展、高可用性、多租户日志聚合系统。它被设计成非常成本效益和易于操作.它不索引日志的内容,而是为每个日志流创建一组标签。
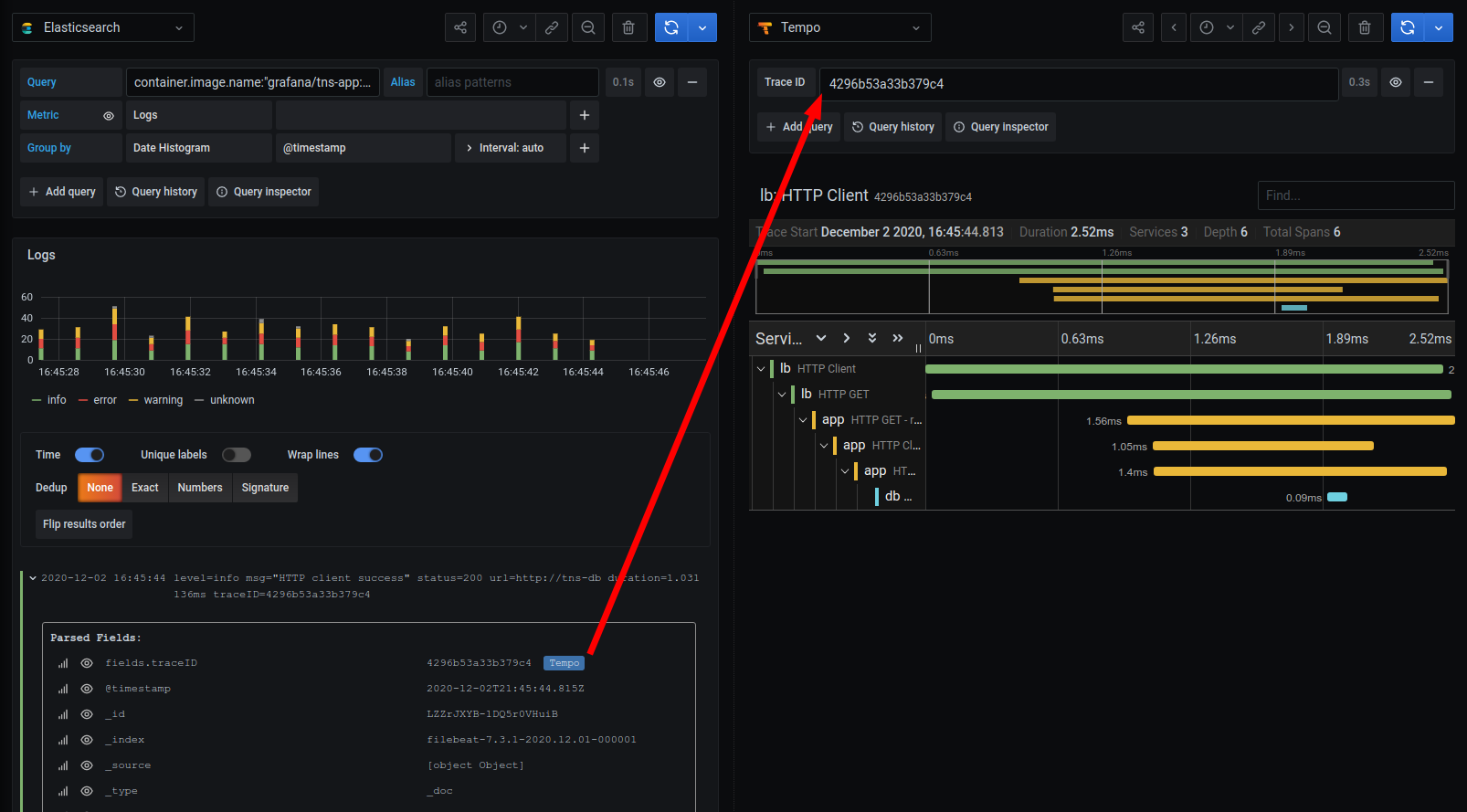
上面显示的查询和日志来自Grafana Labs的一个应用程序。bob电竞频道用户可以查看单个服务并查询服务中发生的所有日志。他们还可以看到一系列的“事件”。或者他们可以跨许多服务进行查询,有时抓取一整套服务,查找特定的错误或一般错误。
但在所有情况下,日志都是在时间上按顺序发生的一系列事件。
最常见的模式之一是,在概述聚合级别,有人会收到警报,或者有人可能会注意到仪表板上的某个指标有问题。接下来的步骤通常是编写一些查询,以大致找出度量引擎中的错误和哪些服务有问题。然后,可以使用日志检索关于特定服务的错误的更详细的信息。
虽然指标和日志可以一起工作来确定问题,但它们都缺乏重要的元素。度量虽然适合于聚合,但缺乏细粒度的信息。日志能够很好地揭示应用程序中依次发生的事情,甚至可能是跨应用程序发生的事情,但是它们不能显示单个请求在服务中可能的行为。
很难跟踪一个请求来了解为什么请求慢。日志将告诉我们为什么服务有问题,但可能不能告诉我们为什么给定的请求有问题。
为什么要进行分布式跟踪?
追踪是所有这些问题的答案。
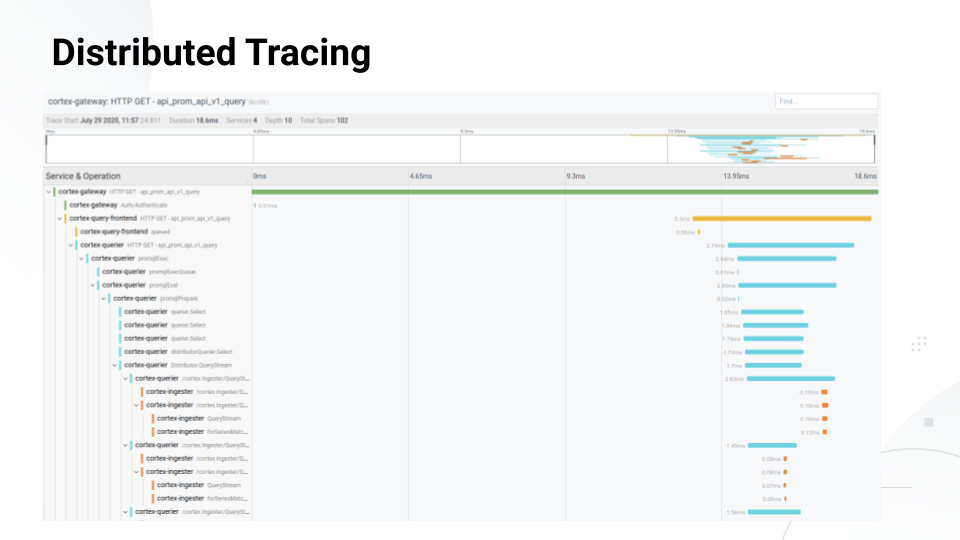
分布式跟踪是一种跟踪单个请求并在它穿过基础设施中的所有服务时记录单个请求的方法。
上面的幻灯片突出了一个普罗米修斯问题皮质,可扩展的普罗米修斯项目提前到CNCF孵化.请求在大约18毫秒内通过4个不同的服务传递,关于如何处理请求有很多细节。如果这个请求花了5秒或10秒或其他很糟糕的时间,那么跟踪可以准确地告诉我们它在那10秒花在了什么地方——也许还可以告诉我们为什么它在某些区域花了时间——以帮助我们理解基础设施中发生了什么,或者如何解决问题。
在跟踪中,跨度是给定应用程序中工作单元的表示,它们由上面查询中的所有水平条表示。如果我们对后端、数据库或缓存服务器进行查询,我们可以将这些查询封装在span中,以获得关于每一部分花费的时间的信息。
跨之间有许多不同的关联方式,但主要是通过亲子关系。在Cortex查询中,有两个相关的spanpromqlEval是父级和promqlPrepare是一个孩子。这种关系就是跟踪后端如何能够获取所有这些跨度,并实际将它们重建为单个跟踪,并在我们请求时返回该跟踪。
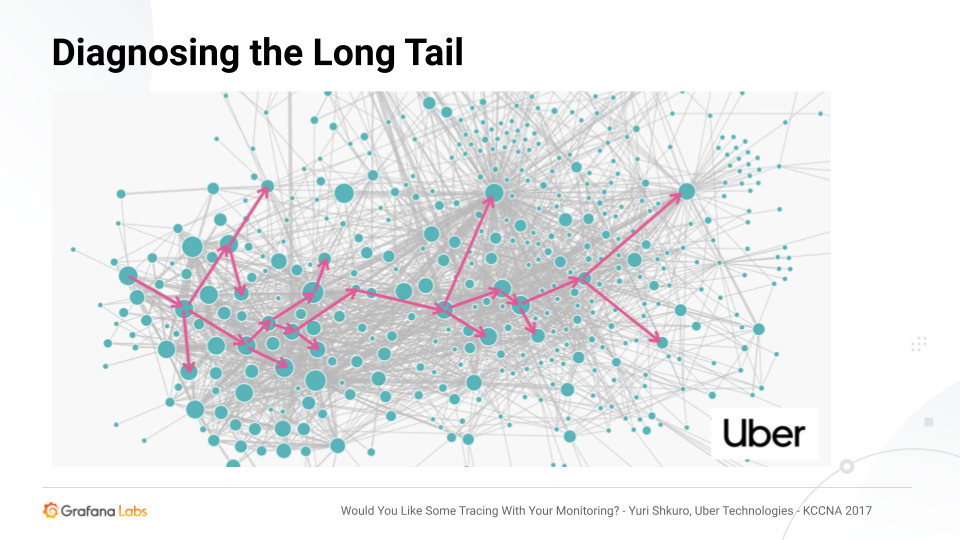
分布式跟踪的最大优势是诊断长尾。
例如,当一组查询到达一个特别复杂的基础设施时,P50可能是正常的,P90可能是15毫秒,但P99可能是5秒——这需要减少。除了这个升高的P99之外,所有的参数看起来都不错。缓存和数据库可以快速响应。那么,为什么有些查询非常长呢?
跟踪是诊断这个问题的好方法。您可以找到这些较长的查询,深入跟踪并真正深入了解查询或请求的确切行为,以便确定将开发工作花在何处。
上面的例子展示了存在于Uber的非常复杂的微服务基础设施,该基础设施开发了流行的开源端到端分布式跟踪系统Jaeger.但是,虽然微服务可以利用跟踪来确定和理解请求是如何通过服务传递的,并获得关于它们的信息,但是跟踪在整体服务中也很有效。
巨石可能非常复杂。它们可以有非常复杂的模块,一个给定的查询可以通过数百或数千个模块,就像一个给定的查询可以通过数百或数千个服务一样。理解在一个整体中执行一个确切查询的方式可能非常困难,但是跟踪也可以解释这一点。因此,分布式跟踪在单一系统或微服务或两者的混合环境中非常有价值。
上下文传播
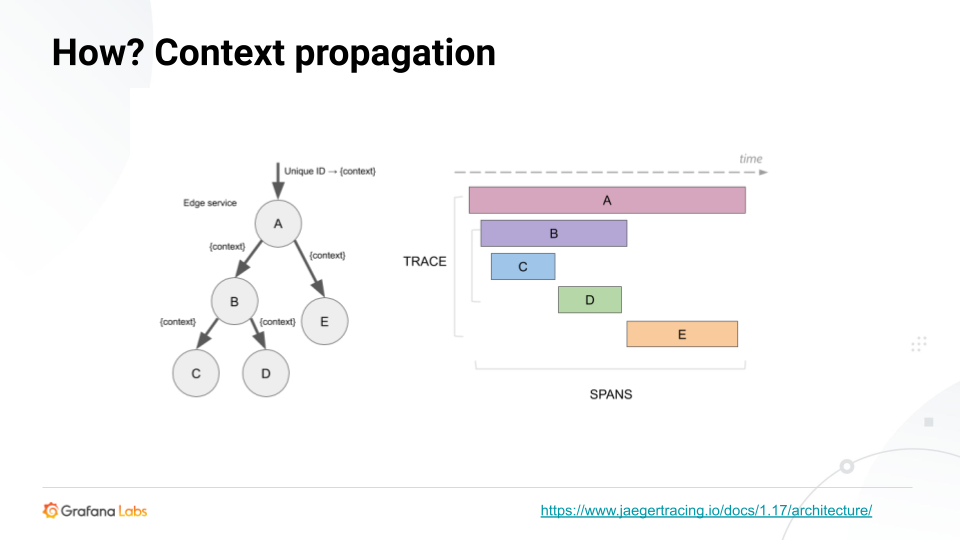
无论是10个服务还是100个服务,它们都在接收请求,它们都在构建描述请求正在做什么的跨度。所有这些跨然后被独立地发送或流传输到后端。所以问题变成了,我们如何重建这些?
这就是上下文传播的用武之地。
开发人员可以有目的地通过HTTP请求传播上下文,以执行跟踪等功能。当您执行请求时,该上下文通过所有函数向下传递,然后还应该传递到下一组服务。
这个上下文是隐藏跟踪信息的地方,例如跟踪ID或父跨度ID,它们在我们将跨度发送到后端时帮助重建跨度。每次你创建一个span时,它会检查context,它会看是否有一个已经存在的span或任何已经存在的trace。如果有,它将成为跟踪的一部分。它将使用该跟踪ID,这将允许后端重新构建。
在服务之间,上下文将附加到HTTP报头或gRPC报头和关于后端查询的元数据。然后,该元数据将跨服务传播跟踪。在服务中,我们使用的是内存中的上下文对象。跨服务时,我们使用头或与查询关联的其他元数据。
跟踪是如何工作的?
你可以点击这里观看演示如何使用一个简单的应用程序,对其进行跟踪,构建跨度,并将这些跟踪卸载到Jaeger后端。在本视频中,您还将看到如何运行一个典型的洛基搜索,从Jaeger检索跟踪,并在Grafana中查看跟踪的工作流。
本文还深入研究了跨,以及如何附加日志、事件或标记等元数据,以便在请求通过体系结构传递时提供更多关于请求中发生的事情的信息。
你可以克隆回购下载Github上的演示,并将其作为参考。
一定要收看2月4日在线研讨会,讨论如何开始使用Tempo有关如何充分利用跟踪的更多信息。
你也可以获得免费的开放测试访问TempoGrafana云.我们有新的免费和付费Grafana云计划,以适应每一个用例-现在就免费注册.


