Splunk Grafana数据源
Splunk数据源允许您查询和可视化Splunk数据搜索处理语言(SPL)或视觉SPL编辑器。
需求
这个插件有以下要求:
- Splunk账户
- 以下账户类型之一:
- 企业启用插件插件
已知的限制
没有已知的限制。
安装的数据源
安装的数据源,请参考安装。
配置数据源
添加一个数据源,请参考添加一个数据源,并填写以下字段:
基本字段
| 场 | 描述 |
|---|---|
| 的名字 | 这个Splunk数据源的名称 |
| URL | 你的访问方法是服务器。URL需要从Grafana后端服务器访问。 |
| 白名单饼干 | Grafana代理删除默认转发饼干。指定你的饼干的名字广域网的数据来源。 |
身份验证领域
- 基本认证
- 输入一个Splunk用户名和密码。避免使用默认管理帐户。(或者,您可以使用一个身份验证标记Splunk细节部分)TLS客户机身份验证
- 内置的选项使用TLS认证(传输层安全)跳过TLS验证
- 可以跳过验证TLS凭证
- 使发送凭据,如饼干或身份验证与跨站点请求头。与CA证书
- 启用验证签名TLS。向前OAuth身份
- 这种身份验证选项是通用的插件身份验证工具包的一部分,但不函数这个数据源。
您可以配置自定义HTTP头由Grafana的配置数据源。这样做允许您添加HTTP头去那个数据源的所有请求。配置的标题名称jsonData场,头的价值secureJsonData字段。
Splunk的细节
身份验证令牌可以使用身份验证令牌代替基本身份验证
- 预览模式
-
(实验)使可用的搜索结果。在引擎盖下,这个选项可以轮询的
工作/ {search_id} / results_previewSplunk API端点。 - 自动取消
-
的秒数,一份工作可以不活跃之前自动取消。默认是30秒。不要自动取消,将
0。 - 民意调查结果
-
运行一个搜索,然后定期检查结果。在引擎盖下,这个选项运行
搜索/工作API调用,exec_mode设置为正常的。在这种情况下,API请求返回工作的SID(安全标识符),然后Grafana定期检查作业状态,为了得到工作的结果。 -
这个选项可以有利于缓慢的查询。这个选项默认是禁用的,Grafana集
exec_mode来一次通过,它允许您在相同的API调用返回的搜索结果。更多的信息搜索/工作API端点,请参考搜索/工作/ {search_id} /结果Splunk的文档。 - 内部字段过滤
-
使隐藏字段的名称
_。 - 内部场模式
- 正则表达式模式,消除内部字段的结果。
- 时间戳字段
- 默认时间戳字段。有关更多信息,请参考时间戳和时间范围。
- 字段搜索模式
- 使用可视化的查询编辑器时,数据源试图得到一个可用字段列表中所选的源类型。
- 快速从预览使用第一个可用的结果
- 完整的等待工作完成完整的结果
- 默认的最早时间
-
时间偏移量格式:
[+ | -]<整数> < time_unit >例如,1 w。时间单位:年代,米,h,d,w,我的,问,y - 通过使用一个默认的最早时间,可以防止搜索生成所有的时间,这可能会减缓Splunk。一些搜索,如模板变量查询,不能使用仪表板时间范围。
- 变量搜索模式
- 搜索模式模板变量查询。
- 快:关闭现场发现事件搜索。没有事件或字段数据统计搜索。
- 聪明的将字段搜索发现了事件。没有事件或字段数据统计搜索。
- 详细的所有事件和现场数据。
数据链接
数据链接通常用于Grafana的探索模式。数据显示一个链接,允许您将数据在内部与其他Grafana数据源,或在外部数据通过一个URL。
建立一个数据链路通过单击+添加按钮下数据链接头在数据源设置。
- 场
-
解析数据。测井资料在Splunk通常返回的
_raw列。 - 标签
-
键和值等
颜色=白色,标签是关键在这个键/值对。 - 正则表达式
-
键和值等
颜色=白色正则表达式解析出的键值对的价值场。正则表达式匹配的正则表达式,所以你必须提供一组匹配的括号表达式。匹配,使用/ (. *)/。你必须包装的正则表达式/ /。
关掉内部链接链接到一个URL基于价值解析Splunk日志。URL:使用变量$ {__value。生}将数据解析与正则表达式的值。您可以使用它来构建一个URL。
打开内部链接使用一个外部链接和链接一个数据源Grafana内另一个数据源。
配置数据源的配置
可以使用配置文件配置数据源Grafana准备系统。你可以阅读更多关于它是如何工作的和所有的设置可以设置数据源配置文档页面
apiVersion: 1数据源:名称:Splunk类型:grafana-splunk-datasource访问:代理basicAuth:真正的basicAuthUser:用户可编辑:真正启用:真正的jsonData: advancedOptions:真正的fieldSearchType:快速internalFieldsFiltration:真正的tlsSkipVerify:真正的variableSearchLevel:快速previewMode:假clusteringStrategy: 1 secureJsonData: basicAuthPassword:密码url: Splunk url版本:1查询的数据源
查询编辑器支持两种模式:spl和视觉。这些模式之间切换点击汉堡图标右边的编辑和选择切换编辑模式。
SPL模式
使用SPL模式通过查询与搜索处理语言(SPL)。SPL上找到更多的信息在这里。
时间序列数据的使用timechart命令。例如:
指数= os sourcetype = cpu | timechart跨度= 1 m avg (pctSystem)系统,avg (pctUser)作为用户,avg (pctIowait) iowait指数= os sourcetype = ps | timechart极限跨度= 1米= 5 useother = false process_name avg (cpu_load_percent)Grafana time-series-oriented应用程序,您的搜索查询返回时间序列数据(时间戳的形式和价值,或一个值)。找到更多的信息timechart命令,请参考timechart。更多的搜索查询的例子,请参考Splunk®企业搜索参考。
Splunk指标和mstats
Splunk 7。x提供了一个mstats命令分析指标,这需要结合timeseries命令才能正常工作。您还必须设置prestats = t选择。
目前的语法:| mstats prestats = t avg (disk.disk_ops.read) avg (disk.disk_ops.write)指数=“collectd”metric_name跨度= 1 m | timechart avg (disk.disk_ops.read) avg (disk.disk_ops.write)跨度= 1 m弃用语法:| mstats prestats = t avg (_value)值指数= metric_name =“collectd disk.disk_ops。读”或metric_name = " disk.disk_ops。write" by metric_name span=1m | timechart avg(_value) span=1m by metric_name更多的信息mstats命令,请参阅Splunkmstats文档。
格式
有两个结果格式模式——的支持时间序列(默认),表。表模式适用于当您想要使用的表面板显示聚合数据。处理(返回所有选定字段)和原始事件统计数据搜索函数,它返回类似于表的数据。结果是相似的统计数据Splunk的UI选项卡。例子:
指数=“_internal sourcetype”=“调度”|字段主机,来源指数= " _internal " sourcetype = " splunkd_access " |统计avg(字节)字节,avg(文件),文件状态阅读更多关于统计数据函数使用Splunk搜索参考
视觉模式
这种模式提供视觉逐步搜索功能。这种模式下创建timechartsplunk搜索通过选择索引、源类型和指标,并根据需要分割的字段。(你如何运行一个可视查询)
度规
您可以添加多个指标通过点击搜索+按钮的右侧规行。指标编辑包含常用的聚合列表,但您可以指定任何其他函数。
- 选择或输入一个聚合类型。默认值是
avg。 - 选择或输入字段的聚合。
- (可选)填写一个别名。
分裂的,
你需要使用时间序列模式使用分裂的。
选择哪些字段将由(这些可以删除下拉选择删除)。
单击+按钮后在哪里选择一个where子句的类型。在where子句中每个函数可以在选择一个where子句类型编辑(选择删除删除where子句的比较器功能)
了解更多在在这里。
选项
了解更多关于timechart选项,请参考timechart。
注释
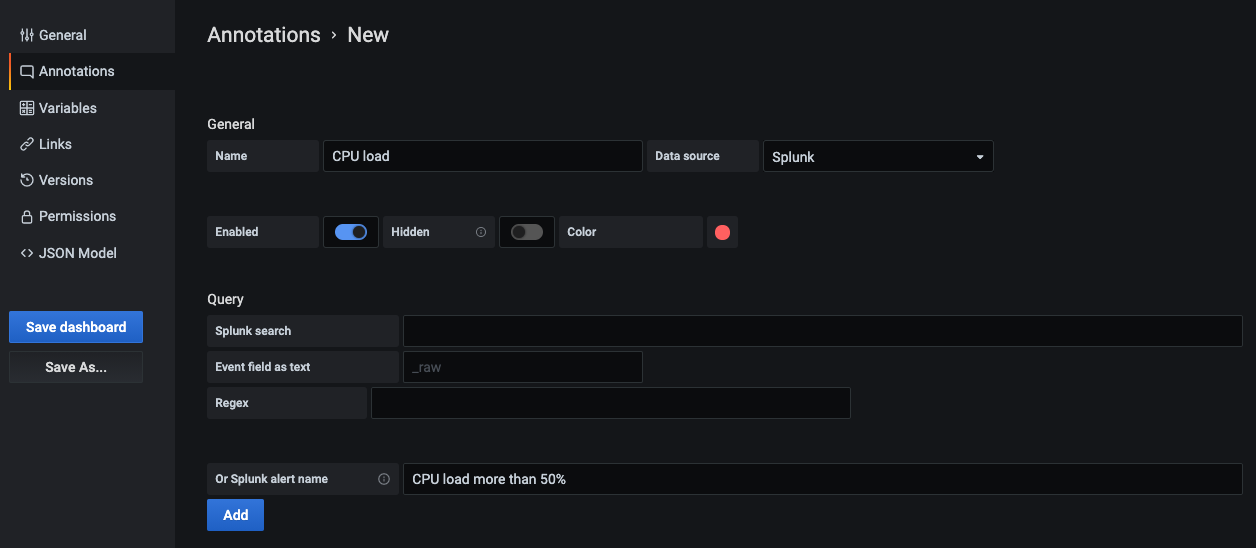
使用注释如果你想显示Splunk警报或事件图。注释可以预定义Splunk警报或定期Splunk搜索。
Splunk警报
指定警报名称或离开字段空白让所有被解雇的警报。支持模板变量。
Splunk的搜索
使用splunk搜索需要的事件,例如:
指数= os sourcetype = iostat | os sourcetype total_ops > 400指数= = iostat | total_ops > io_threshold美元支持模板变量。
事件字段为文本选择合适的如果你想使用字段值作为注释文本。例如,错误消息文本日志:
事件字段为文本:_raw正则表达式:WirelessRadioManagerd \ [\ d * \]: (. *)正则表达式允许提取消息的一部分。
模板和变量
添加一个新的Splunk查询变量,请参考添加一个查询变量。将自己的Splunk数据源作为数据源。
查询与SPL返回的值列表,例如统计数据命令:
os sourcetype指数= = " iostat " |统计值(设备)这个查询返回的列表设备字段值从iostat源。然后您可以使用这些设备名称时间序列查询或注释。
有两种可能的变量类型查询可用于Grafana:
- 一个简单的查询(如上礼物),返回一个值列表
- 一个查询,可以创建一个键/值变量。命名的查询应该返回两个列
_text和_value。的_text列的值应该是唯一的(如果不是唯一的,那么第一个值是使用)。下拉选项将文本和价值,让你有一个友好的名称的文本和一个id值。
这个搜索返回表和列的名字(码头工人容器名称)和Id(容器id):
源= docker_inspect |最新统计计数(名字)名称由Id |表名称、Id为了使用容器名称作为变量的可见价值和id的真正价值,应该修改,查询:
源= docker_inspect |最新统计计数(名字)名称由Id |表名称、Id |名称重命名“_text”, Id作为“_value”多值变量
可以在查询中使用多值的变量。一个插值搜索将根据使用上下文变量。有很多的插件支持的环境。假设有一个变量美元的容器用选定的值喷火和酒吧:
基本滤波器
搜索命令源= docker_stats容器美元= = >来源docker_stats (foo, bar)同一过滤器
源= docker_stats container_name容器= $ = = >来源docker_stats (container_name = foo或container_name = bar)同一过滤器的
在操作员和在()函数源= docker_stats container_name(容器)= = >来源docker_stats container_name (foo, bar)源= docker_stats | container_name在(容器)美元= = >来源docker_stats | container_name在(foo, bar)
多值变量和引用
如果变量用引号(双或单),其价值也将引用:
源= docker_stats container_name = " $容器”= = >来源docker_stats (container_name =“foo”或container_name =“酒吧”)源= docker_stats container_name =“美元容器”= = >来源docker_stats (container_name =“foo”或container_name = '酒吧')在创建一个变量可以使用它在你Splunk查询使用这个语法。
有关变量的更多信息请参考这。
Splunk的导入一个仪表板
遵循这些指令导入一个仪表板。
进口的仪表板可以在配置>数据源>选择Splunk数据源>选择仪表板选项卡可用预先做好的仪表板。
看到指示板当前可用的完整细节仪表板及其数据依赖关系。
指示板
现有以下指示板:
- Kubernetes概述
- 节点的概述
- 豆荚概述
依赖关系
- Splunk 8 -这些仪表板测试Splunk 8.2。
- Grafana > = 8.2
- Splunk OpenTelemetry Kubernetes连接器——这些仪表板被填充,我们需要吸入Splunk Kubernetes数据。目前,仅从这个代理——仪表板利用指标
otelK8sClusterReceiver和otelAgentdaemonset是必需的。我们建议使用执掌图表由Splunk提供。 - Splunk打开连接- - -执掌图表可以用来收集Kubernetes事件。目前,遥测连接器不开放收集这些数据。一旦添加,该代理将不再是必需的。
开立一个仪表板,确保你选择一个合适的指标和事件索引。这些违约em_metrics和主要分别。
Kubernetes概述
这个指示板提供汇总统计集群能力、资源利用率和pod的状态。用户可以通过集群名称和命名空间滤波器。

节点的概述
这个指示板提供汇总统计数据对集群中的节点,它使用户能够通过过滤节点和集群名称。

豆荚概述
这个指示板提供汇总统计数据对集群中的节点,它使用户能够通过过滤舱和集群名称。

了解更多
相关Grafana Splunk数据源资源
统一数据与Grafana插件:Datadog, Splunk, MongoDB等等
在这个网络研讨会,学习如何利用Grafana插件的生态系统来访问80 +的数据来源,包括插件Datadog, Splunk, MongoDB等等。
JIRA, Grafana插件演示:Github, Gitlab ServiceNow等等
在这次研讨会,我们将向您展示如何使用Grafana解锁这些见解和有更好的可见性的表现你的软件开发团队。
所有关于Grafana插件:可视化不同数据源在一个地方
Grafana与其他商业企业插件集成监控工具(如Datadog, Splunk,新的遗迹,ServiceNow, Oracle和Dynatrace)创建、维护和支持的Grafana实验室团队。bob电竞频道
