
Bram Vogelaar是DevOps云工程师工厂最近,他在我们Grafana实验室的EMEA会议上发表了关于可观察性的介绍bob电竞频道.
当我与客户交谈时,他们可能会告诉我他们的应用程序是如何在两个数据中心中运行的,但当我们进一步研究时,发现他们的可观察性堆栈只在其中一个数据中心中可用。
去年3月,这一发现击中了我的要害。欧洲最大的云服务提供商之一OVHcloud经历过一场大火这导致了法国政府等主要客户的大规模中断。
事件发生后的第二天,我负责质量管理的同事问我,如果发生类似的灾难,我们是否能挺过来。这促使我考虑将我们单一的可观察性堆栈演化为跨多个数据中心的高可用性堆栈。
谢天谢地,我们使用的工具比如Grafana节奏用于跟踪和Grafana洛基对于日志记录,可以跨微服务设置进行复制。但是我们能在多个数据中心运行多个实例吗?我们是否处在一个可以“轻松地”失去一个组成部分或整个校园的地方?(也就是说,我们仍然有能力查看应用程序中正在发生的事情吗?)
在最近的Grafana实bob电竞频道验室EMEA会议上,我浏览了我们部署的云原生多数据中心可观察性堆栈,所以上面所有问题的答案都是“是的!”
下面是这个过程的分解。
介绍高
我改进了我的可观察性堆栈并引入领事这是一个开源服务发现工具,具有内置的键值存储和服务网格工具,由HashiCorp构建和维护。
我们可以通过在以下JSON blob中将Grafana定义为领事服务来将服务声明到Consul中:
{"服务":{“检查”:[{“http”:“http://localhost: 3000”,“时间间隔”:“10”}],“id”:“grafana”、“名称”:“grafana”、“港”:3000年,“标签”(“标准”)}}它将允许Consul通过向本地主机发送http请求并在正常状态下向我们的其他平台宣布该服务来检查服务的运行状况。配置完成后,我们可以像任何其他DNS服务器一样查询Consul,询问您的服务的位置。
挖@127.0.0.1 -p 8600 grafana.service.consul ANY甚至可以将Consul合并到数据中心的绑定或非绑定DNS服务器中。
连接领事集群
Consul可以通过联合集群实现多数据中心感知,但它总是使用本地数据中心集群中的数据进行键值存储和服务查询。在我们的示例中,我们有两个相互连接的数据中心——简称为DC1和DC2。
当连接时,Consul集群可以相互识别,但DNS查询不会自动从一个集群到另一个集群。为此,我们需要一个准备好的查询,它可以通过使用curl将以下JSON blob发布到Consul服务器来构建。
curl http://127.0.0.1:8500/v1/query——request POST——data @- << EOF {"Name": "grafana", "Service": {"Service": "grafana" "Failover": {"Datacenters": ["dc2"]}}} EOF . curl: {"Name": "grafana", "Service": {"Service": "grafana上面准备好的名为“grafana”的查询将设置两个集群,以便在DC1中出现故障时,将DNS请求转发到DC2。对于DC2中的Grafana服务,我们设置了相反的查询。在这两种场景中,如果服务中断,它将自动故障转移到另一端,而不会有人注意到,除了Consul需要在短暂的时间间隔内确定本地数据中心的服务已停止。
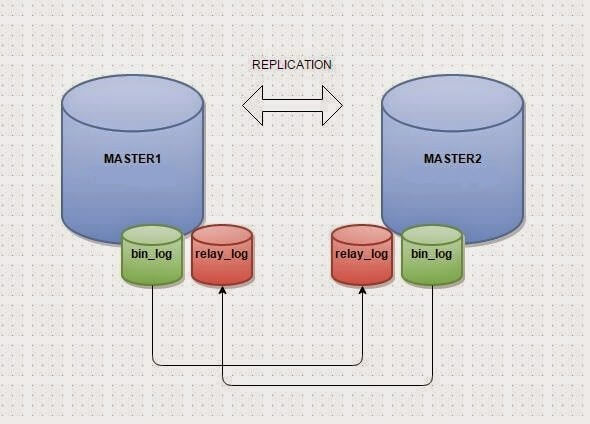
连接Grafana实例
现在我需要想办法同时拥有两者Grafana实例之间相互通信。Grafana有三个数据库后端:SQLite、PostgreSQL和MySQL。SQLite是一个使用磁盘上的本地文件的数据库,它显然无法扩展。PostgreSQL没有开源的主-主复制,所以总是会有一个主数据中心和一个备数据中心在写入数据时存在延迟。我选择的数据库是MySQL,具有主-主复制功能。然后Grafana总是写入本地MySQL,然后将本地MySQL复制到另一个实例,反之亦然。
接下来是在Grafana中更新数据源。您可以轻松地使用用准备好的查询创建的DNS条目作为每个数据源(例如,Loki .query. xml),而不是直接将它们指向本地Loki或Prometheus。领事:3100而不是192.168.43.40:3100)
连接普罗米修斯
我们应该如何实现高可用性普罗米修斯?我们做联邦吗?我们读两遍吗?我们要写两遍吗?
对于这个解决方案,我提出以下建议:Prometheus有一个内置的Consul服务发现选项。因此,我改变了DC1配置,使它使用我的本地Consul集群来发现DC1中声明的所有具有“metrics”标记的服务,这些服务将被刮除。因此,Consul中带有正确标签的所有内容都会自动刮到Prometheus中,从那里您可以构建自己的仪表板。对于DC2,我们复制配置并用DC2替换DC1。
—job_name: DC1 scrape_interval: 10s consul_sd_configs:—server: localhost:8500 datacenter: DC1 tags:—metrics—job_name: DC2…联系格拉芙娜·洛基
对于Grafana Loki,解决方案很简单:您可以配置您的本地Promtail将日志推到两个端点。(注意:我在这里使用IP地址而不是查询,因为我想确保我写了两次。)
客户端:—url: https://192.168.43.40:3100/loki/api/v1/push—url: https://192.168.43.41:3100/loki/api/v1/push连接Grafana节拍
Grafana Tempo是配置起来最具挑战性的工具。我们问了很多我们在整个堆栈中做过的相同的问题:发送两次?写两次?读过两次吗?
接下来的问题是:我们是否要引入代理?
这就是Grafana代理下面是配置:
Tempo:配置:—name: default receivers: zipkin: remote_write:—endpoint: 192.168.43.41:55680—endpoint: 192.168.43.40:55680在Grafana代理在v0.14版本中,他们为Tempo发布了“remote_write”,使其成为我们所需要的优秀代理。
在我们的用例中,我的所有跟踪代理都使用Grafana Agent作为端点,而不是直接推入Tempo,然后它们远程写入我的两个Tempo实例。这需要对配置进行一些更改:在本例中,Grafana Agent现在有一个接收器Zipkin,写进两个不同的端点。一个是我的本地数据中心,另一个在第二个(故障转移)数据中心。
现在我们要用接收器OpenTelemetry数据,监听不同的端点和不同的端口,因此确保您的防火墙进行了相应的调整。(相信我,那是我生命中的两个小时,我再也回不去了!)
分配器:接收器:拉链:distribution: receiver: otlp: protocols: grpc:连接Alertmanager
对于Alertmanager HA,它要简单得多!您从一个附加的标志开始,它基本上是说,我是一个集群,我的同伴位于以下端口上。然后他们开始沟通和删除重复的警报。在《普罗米修斯》中,你需要为自己的《普罗米修斯》添加一个额外的目标。yaml文件。
[单位]ExecStart=/usr/local/bin/alertmanager \——config.file=/etc/alertmanager/alertmanager. exeYaml \—存储。Path =/var/lib/alertmanager \——cluster.advertise-address=192.168.43.40:9094 \——cluster.peer=192.168.43.41:9094Alerting: alertmanagers:—static_configs:—targets:—192.168.43.40:9093—192.168.43.41:9093结论

在我完全复制的可观察性设置中,我不需要复制所有的代码行,因为那基本上会变成一个大的混乱。相反,我添加了所有必要的额外行和所有关键组件,以便在两个不同的数据中心运行相同的堆栈。现在我可以杀死任何元素,或者整个数据中心,知道我仍然有一个完整的可观察性堆栈。
跟得上Grafana Agent在GitHub上的开源项目并加入讨论#代理频道上bob电竞频道Grafana实验室社区Slack.
想与社区分享你的Grafana Agent技巧吗?给我们留个便条stories@www.tubolov.com.


