
Tinder是世界上最受欢迎的约会应用程序,每天有超过2600万对配对。但两年前,当这家总部位于洛杉矶的公司需要寻找并实施一个完美的指标监控合作伙伴时,事实证明,这个过程更像是一场慢燃的恋爱,而不是昙花一现的浪漫。
“他们说罗马不是一天建成的。Tinder的Grafana基础设施也是如此,“Tinder可观察性软件工程师龚文婷告诉观众在Grafanacon 2019在洛杉矶
自2012年成立以来,易燃物已经发展到超过320名员工,并利用Grafana监控其Kubernetes环境中的数百个微服务和容器。
Tinder与Grafana的关系是这样发展的。
第一印象:右滑Grafana
2017年,Tinder有大约50个微服务在运行Amazon EC2实例,CloudWatch监视和弹性负载平衡器支持。云基础设施团队与可观察性团队一起开始构建一个内部基础设施,以监控Tinder所有服务的整体健康状况。
“因为一切都在AWS上运行,AWS CloudWatch可以提供这些有用的指标,”Gong说。“Grafana是一个非常流行的开源工具,用于应用程序和基础设施的数据分析和可视化,所以他们决定在这些实例上启用我们的CloudWatch,以及弹性负载均衡器和自动伸缩组。”
通过从CloudWatch数据源(这是Grafana的原生数据源)提取指标,Grafana允许工程师直接查看和检查他们的服务指标,并创建一个集中的位置来访问实时指标。简而言之,Tinder喜欢Grafana的个人资料,向右滑动,享受与监控系统的早期互动。
与家人见面:介绍普罗米修斯
Tinder的后端工程师很快就决定更好地了解Grafana。他们希望使用它来监控服务的效率,创建仪表板来跟踪P95延迟或请求状态更新。
在研究时间序列数据库选项的范围时,云基础设施团队调查了OpenTSDB(“它需要Hadoop,这并不适合我们的场景,”Gong说)、Graphite(“对于开源解决方案来说很难扩展”)、InfluxDB(“它的集群功能可以作为付费版本使用”)和Nagios(“它是一代旧的”)。
Gong说:“Prometheus没有任何这些突出的缺点,它提供了很棒的客户端库,所以开发者可以使用它直接从他们的代码中公开他们的应用程序指标。”“所以普罗米修斯号是我们的最佳选择。”
一个单一的普罗米修斯该公司推出了一个服务器,为Tinder的所有服务提取指标,Grafana用于监控服务详细的市场指标以及CloudWatch的内部指标。但蜜月期并没有持续太久。
几个月后,后端工程师发现,随着Tinder业务的持续快速增长,数据不时被删除。一台普罗米修斯服务器不足以承载这款约会应用蓬勃发展的服务。
解决方案是创建一个更可扩展的基础设施,包括为Tinder套件中的每个服务分配单独的Prometheus服务器,并在Grafana上为每个服务创建单独的仪表板。这个解决方案不仅使基于服务负载扩展单个Prometheus服务器变得容易,而且“通过启用不同的Prometheus服务器和记录规则,这个基础设施还增强了那些经常使用的表达式和那些计算昂贵的表达式的当前性能,”Gong说。
认真对待:致力于长期数据
由于监控被证明对Tinder的业务很有价值,后端团队希望能在更长的时间内访问指标。
Gong解释道:“我们只为每项服务保留了几天的指标。“但(工程师们)仍然希望检查一些重要数据的历史指标。”
解决这个问题有两个选择。Gong说道:“其中一个方法便是延长Tinder所有Prometheus服务器的留存时间,这非常简单。但由于并非所有数据都是长期留存所需要的,“金钱和资源将浪费在不必要的指标上。”
可观察性团队随后建议启动一个单独的Prometheus服务器,严格用于存档关键指标,工程师可以根据需要随时访问。
新创建的服务器将从所有单独的Prometheus服务器中提取指标,并将其作为Grafana上的独立数据源公开。Gong说:“此外,我们在存档服务器中运行数据自动发现服务,因此无论何时出现或删除新服务,数据源、目标和端点都会在存档服务器端和Grafana端进行更新。”
Gong补充道:“尽管这种方式需要额外的设置,模块所有者需要了解和更新现有的配置,但这有助于我们以更有效的方式使用资源和预算。”
同居:迁移到Kubernetes
随着Tinder的微服务开始增加到数百个,云基础设施团队决定是时候转移到Kubernetes环境了,这将帮助工程师大规模部署和管理应用程序。龚说:“通过这种方式,它将帮助我们的开发人员提高速度、效率和灵活性,还将帮助我们节省一些资金。”
因此,可观察性团队必须弄清楚如何在Kubernetes中执行和支持当前的监控基础设施,这涉及到在不同集群的不同名称空间中运行的不同服务。
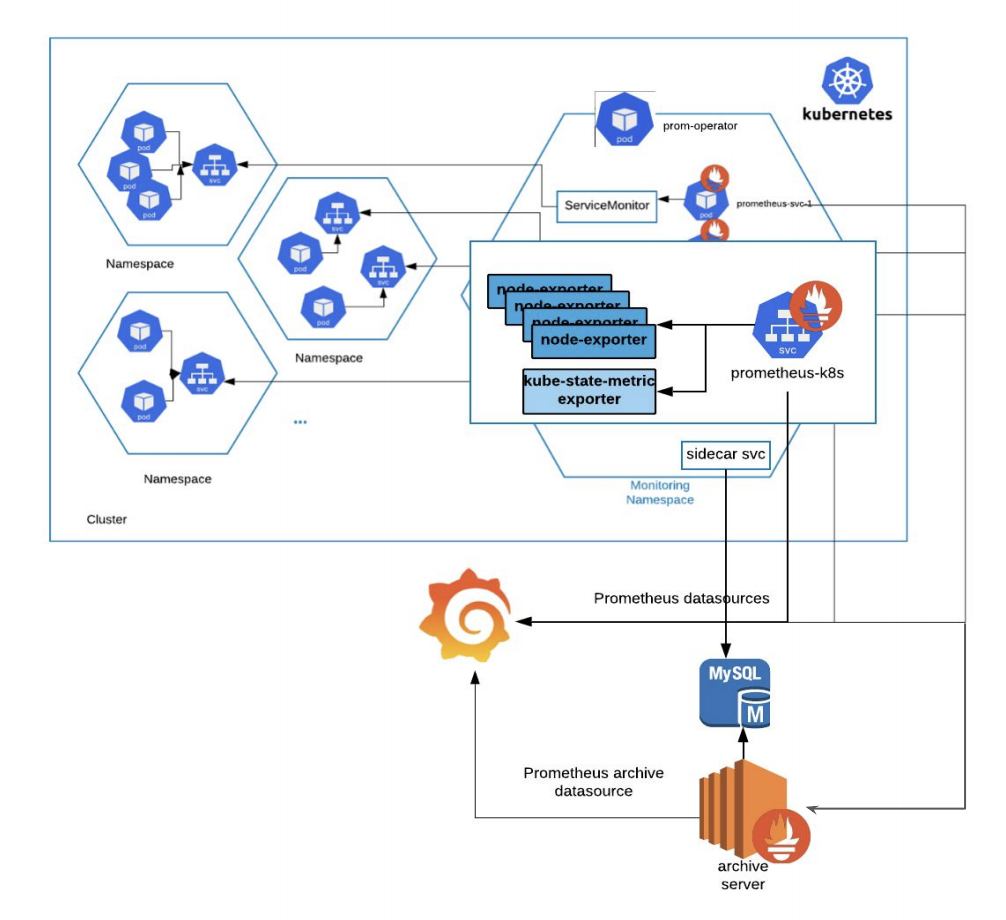
因为开发人员已经熟悉使用Prometheus来公开应用程序指标,所以实现一个新系统没有意义。相反,Tinder推出了普罗米修斯操作员在Kubernetes环境中管理、创建和配置Prometheus实例的监控命名空间。龚说:“服务监控器将帮助我们选择我们试图监控的目标,普罗米修斯服务本身将从这些服务监控器中提取指标。”“这个Prometheus服务端点也作为一个单独的Prometheus数据源公开给Grafana。”
在监视名称空间中,还专门为存档的指标设置了单独的sidecar服务,以收集Prometheus数据并将它们放入单独的MySQL数据库中。Gong说:“存档服务器位于传统的EC2实例中,它将检查这些数据库结果,提取这些目标指标,并将自己暴露为一个单独的普罗米修斯存档数据源。”
如果Kubernetes环境中有任何紧急问题该怎么办?可观测性小组为Kube星团本身建立了一个监测系统。Gong说:“我们在监控名称空间中推出了一些节点导出器,一个kube-state-metric导出器,并使用单独的普罗米修斯节奏来引入这些kube相关的度量。”“这种与Kube相关的节奏也是Grafana绘制与Kube状态相关图表的独立数据源。”
Tinder还使用Prometheus导出器来监控其他基础设施组件,如Elasticsearch和Kafka。
Tinder的基础设施被安置在Kubernetes环境中,工程师现在可以轻松监控测试环境。“但对于我们的工程师来说,为类似的模块在不同的环境中复制这些仪表板是一件令人头疼的事情,”龚说。
为了减少手工创建工作,Tinder使用了许多由Grafana支持的api。Gong说:“在GrafanaLib的帮助下,我们在Python中使用HTTP客户端包装器开发了定制的仪表板自动化实用程序,这将有助于为不同的集群和不同的环境复制类似的仪表板。”
简而言之,这是一种长久的关系。


