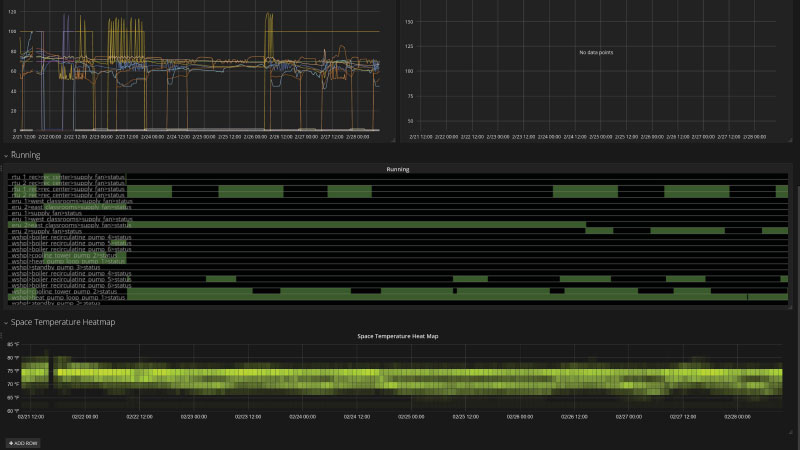
超过155万晚的房间被预订Booking.com每天站台。这是一个惊人的流量,毫不奇怪,这家总部位于阿姆斯特丹的旅游电子商务公司有很多关于大规模处理指标的知识可以分享。
在2018年欧盟GrafanaCon上,Booking.com系统管理员Vladimir Smirnov发表了一篇演讲说话为什么公司开始使用石墨大约五年前,以及他和他的团队如何将其扩展到每秒处理数百万个参数。他打趣道:“据graphiteapp.org网站称,Graphite在三件事上做得非常好:它很厉害,能嚼泡泡糖,而且它可以很容易地存储和绘制指标。”通过HTTP API的易用性及其模块化是Booking.com的一大吸引力。
在组织中,Graphite最常见的用例是容量规划和故障排除。他说:“对于容量规划,我们确实需要存储相当长一段时间的数据,最好是永远存储。”“此外,我们希望将其用作故障排除和事后分析的数据来源。我们决定存储和可视化业务指标,所以无论开发人员认为应用程序需要什么,他们都会将其发送到那里。”
大规模石墨的挑战
多年来,Booking.com的Graphite发展到由数百个服务器组成。斯米尔诺夫说:“这是数百tb的数据,数以亿计的独特指标。”“它每秒吸收超过1000万个独特点,我们在被监控的堆栈的前端和后端每秒都有数万个请求。所有这些请求每秒从磁盘的存储中获取1000万个点。这还不包括从缓存中获取的东西。”
2014年构建的原始堆栈需要几个具有完全相同设置的数据中心。斯米尔诺夫说:“你最终会拥有石墨网络和一堆与存储服务器通信的服务器、容器或虚拟机。”“你将在摄入流上拥有某种负载均衡器,服务器和设备将发送它们的指标。”
这里面有一些固有的问题:“碳接力对我们来说真的是一个单点故障,”他说。“第二个问题是,对于我们的案例,后端并不能很好地扩展。碳缓存过去使用了大量的CPU。我们不喜欢磁盘使用模式。此外,如果我们有一些存储故障,也没有简单的方法来同步我们的数据。例如,一个存储耗尽,第二个存储离开,然后第二个存储返回,用户每次刷新都会得到不同的结果,这取决于谁先想要它。所以渲染请求对我们来说真的很慢。”
重写继电器
为了解决单点故障的问题,Booking.com的Graphite团队用C重写了继电器.他说:“我们决定在尽可能靠近指标生产者的地方放置一个中继,这样每个服务器都有一个小型中继,它知道几个更大的端点——基本上每个数据中心都有几个中继。”中央中继了解存储和如何平衡度量,并具有消除某些内容或将其重写为其他内容的规则。
继电器提供了冗余和速度。斯米尔诺夫说:“仅使用两个CPU核心,它就可以每秒消耗超过100万个数据点,这对我们来说是一个非常理想的功能。”
使用石墨线协议,中继读取度量,验证它们,并决定将它们发送到哪里。重要的是,如果出现网络或节点故障,它可以缓冲一段时间的数据,并且在大多数停机情况下不会丢失数据。
但该公司的石墨之旅并未就此结束。斯米尔诺夫说:“我们得到的指标越多,我们开始注意到的奇怪的东西就越多。“首先,我们看到,大容量流一致性哈希算法的度量分布不是很好。在最糟糕的情况下,差异约为20%,所以基本上当一台服务器耗尽磁盘空间或容量时,其他服务器都没问题。”
研究小组发现来自谷歌的关于跳转哈希算法的白皮书,并在中继中实现,实现了几乎均匀的分布。与新算法的差异小于1%。
最近,他们意识到这种实现不容易维护,所以他们开始这样做在围棋中重写中继.他们还尝试从传统的明文碳协议输入和输出转换到开始使用Kafka。
处理度量之间的差异
在最初的2014年堆栈中,“当一个服务器死后,一段时间后它又出现了,人们将开始看到不同。”他补充说:“每次他们刷新图表时,他们都会看到不同的结果,因为两台服务器获得了不同的数据量。”
他们解决这个问题的方法很简单:他们写了一个位于前端的小代理,模拟石墨网的行为,从所有已知的包含该指标的后端获取数据。他说:“如果内部有任何空白,它将尽力填补空白,并向用户提供全套数据。”这个解决方案几乎把问题减少到零。他说:“仍然有一些罕见的情况会发生,但普通人几乎察觉不到。”
他们还决定用一个叫做去碳.Smirnov说:“我们为它贡献了一些代码,以允许阅读度量标准,并以石墨网络期望的方式呈现它们。”“这也解决了一些查询速度的问题,因为在我们的测试中,Graphite web查询碳缓存允许我们每秒执行80个请求,在用Go重写之后,每个后端每秒几乎可以执行3000个请求。”
使Grafana
斯米尔诺夫的团队安装了Grafana,“人们非常喜欢它,因为它比石墨网要好得多,”斯米尔诺夫说。“通过使用它,他们开始做越来越复杂的查询,更复杂的仪表盘,从速度和其他方面来看,这再次成为一个问题。”他们决定用Go来编写石墨网的一些部分。“这导致前端的平均响应时间显著减少,”他报告说。“基本上,这就是我们推出的时刻碳API作为Grafana的主要数据源。平均响应时间从15秒左右减少到不到1秒。”
Booking.com在函数和解析特性方面所做的所有工作都可以作为Go库使用。
改进后端
用于为后端存储数据的一种具有弹性和故障安全的方法是Replication Factor 2。然而,团队用于在Graphite上执行操作工作的后端工具不能与Replication Factor 2一起工作。他们尝试使用Replication Factor 1,发送两次,将服务器舰队手动分成两个相等的部分,并将其发送到不同的部分。
为了选择使用哪种方法,他们创建了一个复制因子试验计算服务器故障时数据丢失的可能性。对于一组8台服务器,该团队发现使用Replication Factor 2会比使用Replication Factor 1丢失更少的数据。但是,当两台复制因子2服务器出现故障时,总会有一小部分数据肯定不可用。使用Replication Factor 1,当两台服务器故障时数据丢失的概率只有15%。该团队选择在两组不同的服务器中使用Replication Factor 1,以降低丢失数据的概率。
更多问题需要解决
Booking.com拥有数百个服务器和人员,面临着一些特殊的挑战。斯米尔诺夫说:“有时你会得到这样的信息:警告:磁盘空间使用显示你还有10%的剩余空间,请提供新的服务器。”“但问题是,你5分钟前检查了一下,还剩20%,那么到底是谁创造了这些奇怪的新东西?”
事实是,“因为向Graphite发送数据非常容易,所以很容易被滥用,”Smirnov说。例如,你可以意外地获得变量的地址并发送它,而不是变量名。应用程序的每个实例都会创建一堆名称奇怪的指标。除非你真的遇到这样的事情,否则你永远不会知道。”
为了找到解决方案,团队开始收集关于后端所有可能的统计信息,关于文件的所有元信息:最后一次访问的时间,创建的时间,大小。使用在Github上找到的一个库,该团队在火焰图.
Smirnov说:“当你有一些可以被认为是好的数据点时,就很容易切换到下一个数据点并查看差异,这样你就可以很容易地发现它发生在哪里,并判断一个指标是合法的,还是有人意外创造了它。”“这也使我们能够在所有数据集上进行大量分析查询:人们如何使用我们的堆栈,最常请求的指标是什么,等等。99%的指标没有人关心,但最后1%的指标非常热门,我们可以在此基础上进行优化。”
接下来是什么
该团队有一个实质性的待办事项清单,以不断改进Booking.com的石墨堆栈。
- 找一个whisper的替代品,因为它没有任何压缩。“每个点有12个字节,所以占用了大量的磁盘空间,而我们的大多数空缺实际上是磁盘空间有限的,而不是CPU、内存或网络的限制。”
- 替换组件之间的Graphite线路协议。“我们期待着迁移到流gRPC,但就摄取而言,它仍然是跨所有堆栈的行协议。第一步之后你就不需要它了。你可以使用一些压缩的甚至二进制的东西来避免在后端花费CPU时间。”
- 让火焰图或多或少地为其他用例做好生产准备,甚至可能有像差分火焰图这样的东西。
- 开始从生产中的Graphite堆栈中收集堆栈跟踪,以了解当我们遇到问题时底层发生了什么。
TL /博士
虽然该团队认为石墨堆栈仍在进行中,但Smirnov可以推荐他们经过五年的实验和故障排除后得出的基本设置。他说:“我们真的很惊讶,不仅我们自己在使用我们的堆栈,eBay分类和Slack还在使用我们的堆栈的一部分。”
总结一下:“每个前端都有三部分软件-Grafana,碳API和Carbon Zipper(包含在Carbon API中)-每当前端出现问题时,我们只需部署一个包含这三个部分的新服务器,”Smirnov说。“对于后端来说,总是如此去碳在内部启用carbonserver。这始终是一个单一进程,每当我们耗尽磁盘空间,或者在极少数情况下,当我们达到容量限制时,比如我们每秒可以从存储端接收的指标数量,我们就会部署一堆新服务器,并进行重新平衡buckytools.”
现已离开Booking.com的斯米尔诺夫保留了原著碳API项目他在那里的时候就开始研究了。预订的当前堆栈可以在其GitHub帐户.有关更多详细信息,请查看幻灯片从他的演讲中。